Wide & Deep 是 Google 发表在 DLRS 2016 上的《Wide & Deep Learning for Recommender System》。Wide & Deep 模型的核心思想是结合线性模型的记忆能力和 DNN 模型的泛化能力,从而提升整体模型性能。Wide & Deep 已成功应用到了 Google Play 的app推荐业务,并于TensorFlow中封装。该结构被提出后即引起热捧,在业界影响力非常大,很多公司纷纷仿照该结构并成功应用于自身的推荐等相关业务。
模型
Wide&Deep模型的初衷是融合高阶和低阶特征。原始模型里面:wide部分是特征工程+LR,deep部分是MLP(多层感知器(Multilayer Perceptron,缩写MLP))。
Wide&Deep是一类模型的统称,将LR换成FM同样也是一个Wide&Deep模型。
后续的改进如下:
- DCN/DeepFM是对wide部分的改进,将LR替换为CN,FM等。
- NFM是对Deep部分的改进,加入特征交叉层Bi-interaction。
本文讨论最原始的模型,结构如下
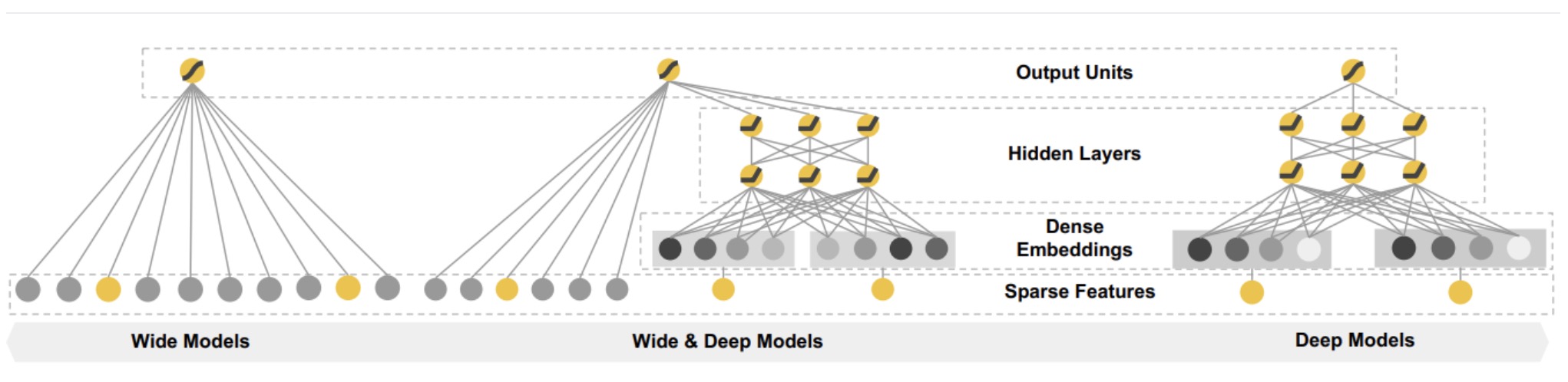
Wide&Deep全文围绕着“记忆”(Memorization)与“扩展(Generalization)”两个词展开。实际上,它们在推荐系统中有两个更响亮的名字,Exploitation & Exploration,即著名的EE问题。
- 记忆(memorization)即从历史数据中发现item或者特征之间的相关性;哪些特征更重要——Wide部分。
- 泛化(generalization)即相关性的传递,发现在历史数据中很少或者没有出现的新的特征组合;——Deep部分。
在推荐系统中,记忆体现的准确性,而泛化体现的是新颖性。
Wide
wide部分是一个广义的线性模型,输入的特征主要有两部分组成,一部分是原始的部分特征,另一部分是原始特征的交叉特征(cross-product transformation)。
Wide侧记住的是历史数据中那些常见、高频的模式。Wide侧没有发现新的模式,只是学习到这些模式之间的权重,做一些模式的筛选。正因为Wide侧不能发现新模式,因此我们需要根据人工经验、业务背景,将我们认为有价值的、显而易见的特征及特征组合,喂入Wide侧。
Deep
Deep部分是一个DNN模型,输入的特征主要分为两大类,一类是数值特征(可直接输入DNN),一类是类别特征(需要经过Embedding之后才能输入到DNN中)
Deep侧,通过embedding+深层交互,能够学交叉特征。
Wide&Deep
W&D模型是将两部分输出的结果结合起来联合训练,将deep和wide部分的输出重新使用一个逻辑回归模型做最终的预测,输出概率值。
损失函数 模型选取logistic loss作为损失函数,此时Wide & Deep最后的预测输出为:
优缺点
优点
- 简单有效。结构简单易于理解,效果优异。目前仍在工业界广泛使用,也证明了该模型的有效性。
- 结构新颖。使用不同于以往的线性模型与DNN串行连接的方式,而将线性模型与DNN并行连接,同时兼顾模型的Memorization与Generalization。
缺点
Wide侧的特征工程仍无法避免。