什么是 word embedding
参考:https://www.zhihu.com/question/32275069
Embedding在数学上表示一个maping, f: X -> Y, 也就是一个function,其中该函数是injective(就是我们所说的单射函数,每个Y只有唯一的X对应,反之亦然)和structure-preserving (结构保存,比如在X所属的空间上X1 < X2,那么映射后在Y所属空间上同理 Y1 < Y2)。那么对于word embedding,就是将单词word映射到另外一个空间,其中这个映射具有injective和structure-preserving的特点。
通俗的翻译可以认为是单词嵌入,就是把X所属空间的单词映射为到Y空间的多维向量,那么该多维向量相当于嵌入到Y所属空间中。
word embedding,就是找到一个映射或者函数,生成在一个新的空间上的表达,该表达就是word representation。
推广开来,还有image embedding, video embedding, 都是一种将源数据映射到另外一个空间
常用word embedding方法包括word2vec,glove
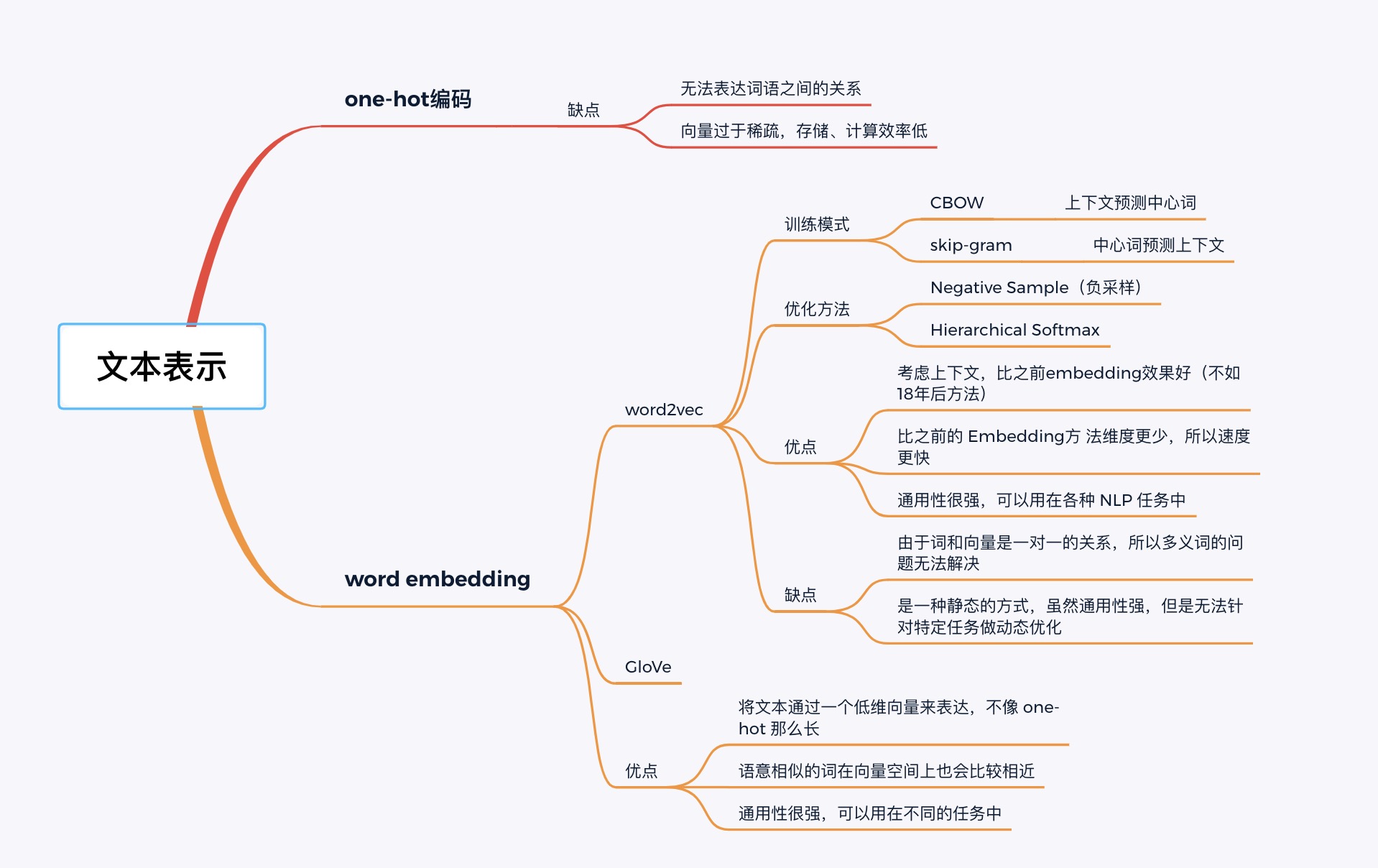
Word2Vec
参考:http://ywtail.github.io/2017/06/09/TensorFlow-6-%E5%AE%9E%E7%8E%B0Word2Vec/
Glove
参考:http://www.fanyeong.com/2018/02/19/glove-in-detail/
N-Gram
N-Gram是一种基于统计语言模型的算法。它的基本思想是将文本里面的内容按照字节进行大小为N的滑动窗口操作,形成了长度是N的字节片段序列。
每一个字节片段称为gram,对所有gram的出现频度进行统计,并且按照事先设定好的阈值进行过滤,形成关键gram列表,也就是这个文本的向量特征空间,列表中的每一种gram就是一个特征向量维度。
该模型基于这样一种假设,第N个词的出现只与前面N-1个词相关,而与其它任何词都不相关,整句的概率就是各个词出现概率的乘积。这些概率可以通过直接从语料中统计N个词同时出现的次数得到。常用的是二元的Bi-Gram和三元的Tri-Gram。
FastText
fastText是Facebook于2016年开源的一个词向量计算和文本分类工具,在学术上并没有太大创新。但是它的优点也非常明显,在文本分类任务中,fastText(浅层网络)往往能取得和深度网络相媲美的精度,却在训练时间上比深度网络快许多数量级。在标准的多核CPU上, 能够训练10亿词级别语料库的词向量在10分钟之内,能够分类有着30万多类别的50多万句子在1分钟之内。